











Easy, hard, sometimes impossible: what do we do to develop Background Remover, and what’s the most challenging? (Spoilers: it’s not about drawing around your hair).
Background Remover should work just like that: users upload content, click the button, and receive the exact result that they need. Is it only about clipping the background out? Not really.
How did it start
This product has come a long way in development. As the primary dataset, we used photos from our photo library, Moose, and our retouchers manually clipped objects in the photos. To train our neural network, we pass to the AI an object with a background and an object without a background, and the AI learns from these examples. Basically, the result of a real person’s work became an example for an AI.
Just cut it out
In some cases, our tool already meets the user’s expectations. Background Remover does an excellent job with images that focus on one subject. Here it performs as a real one-click tool.

But if you start training the network just to cut out a simple background and collect a dataset of objects on a solid-colored background only, the neural network will learn to remove the color, not the background. This will not work on real data. Users upload any pictures they want with different types of backgrounds or scenes. Which of these should we include?
Clip it or leave it?
In real life, we often face questionable situations where our neural network has human-like concerns about the user’s purpose.
For what exactly do you need it?
There are several elements here, and the neural network detected them all and “chose” to include them in the result:

Yes, Background Remover did a great job with these two men in the background, but they’re out of focus and blurry. Thus, it makes it impossible to use them in other scenes. It’s hard to come up with a context where it would be appropriate. Do the users need these objects in their results?
This is how we came up with the principle of portability: to what extent can we reuse a cut-out object in another scene?
In the example above, from the point of this principle, our tool did not work quite as it should. This is one of the directions in which we are now developing our AI.
Who is the main character of the scene?
Sometimes an object is only partially clipped, this means that the neural network itself is not certain whether to clip it or not. Here is an example of AI’s uncertainty:
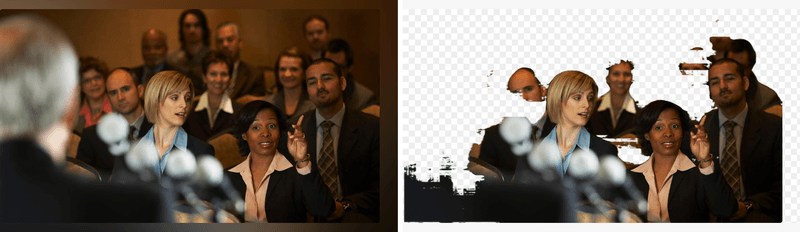
For the human eye, it is a feasible task to tell that these two women in the camera’s focus are more likely the ones that the user needs. But here, even for us, it is difficult to say what is the main thing in the composition:

When persons are interacting with an objects
Should we include the object when a person interacts with it? How to understand the difference between necessary and unnecessary objects and their parts in the image? To train our AI, we usually clip the people along with the objects that the people in the photo are interacting with. However, here we see that sometimes Remover doesn’t define the object’s borders completely.

Salient object detection
As you see, the detection of the scene is something that just doesn’t have a correct answer. When the neural network must determine significant objects and highlight them, there is Salient object detection.
In our training process, we have divided images into several subclasses: simple images with one object on a plain background, portraits, landscapes, and illustrations. There are two possible approaches: train the network on each class separately, or balance the dataset so that it covers everything. We choose to follow the second.
The main challenge of this approach is not to create the datasets themselves but to understand if somewhere it has become worse after retraining the network. There are metrics that show improvements in numbers, but visually the result may become worse, even though the numbers are growing in reports. We can not rely only on stats, so we should always have a finger on this process’s pulse. Nobody wants to throw the baby out with the bathwater.
So, what’s next?
Well, in a not far future, we strive to make Background Remover a tool that divides the image into layers that can be switched on and off by the user. Also, the neural network can even draw new objects and backgrounds by itself to replace the removed ones, but these are already far-reaching plans.




